Calculated Fields#
Calculated Fields play a crucial role in analyzing and interpreting business data, empowering users to generate custom fields. Through Calculated Fields, users can craft personalized fields for future reference. It’s important to note that the custom field created using Calculated Fields will exclusively exist within the platform and won’t be replicated in the actual database.
Creation of Calculated Fields#
Here is a comprehensive guide on how to work with Calculated Fields in your business:
Step 1: Upon successful login, you will be directed to the platform’s Storyboard, To access calculated fields, you need to access the Data Management feature in the Data Workbench.
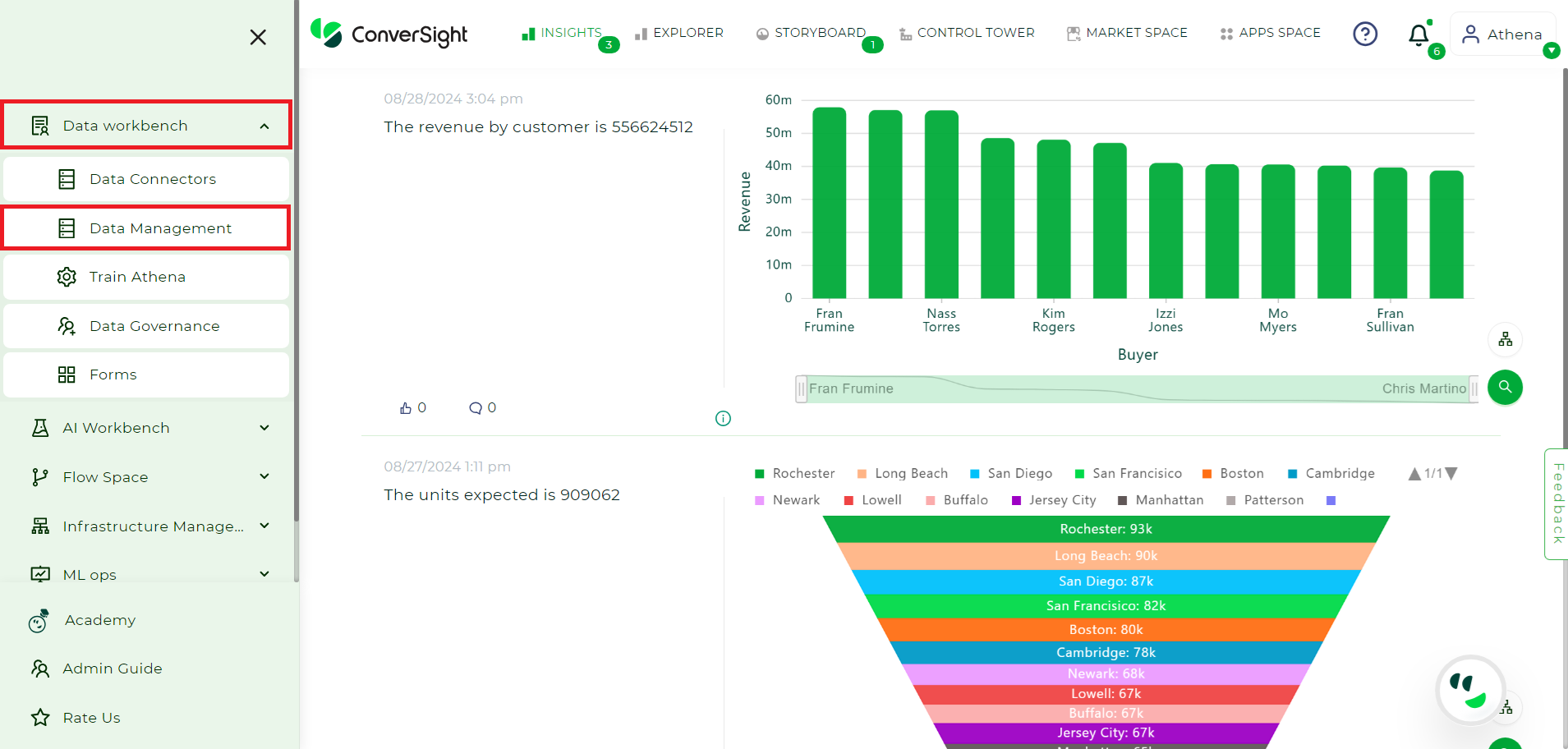
Landing Page#
Step 2: Select the dataset for which the Calculated Fields has to be created and go to Setting icon in the Action column of the Data Management and select Configure SME.
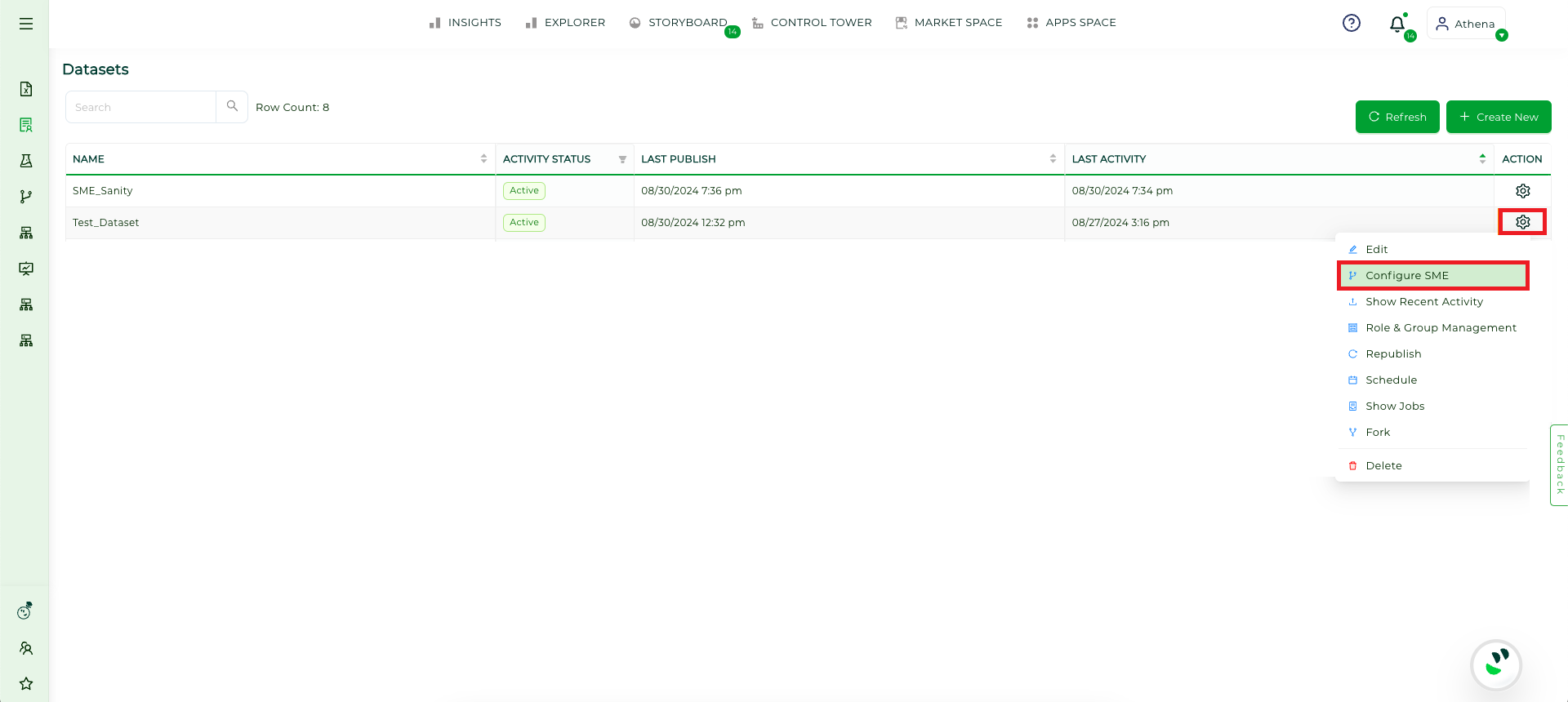
Configure SME#
Step 3: Once you’re on the SME Coaching page, click on the Table tab.
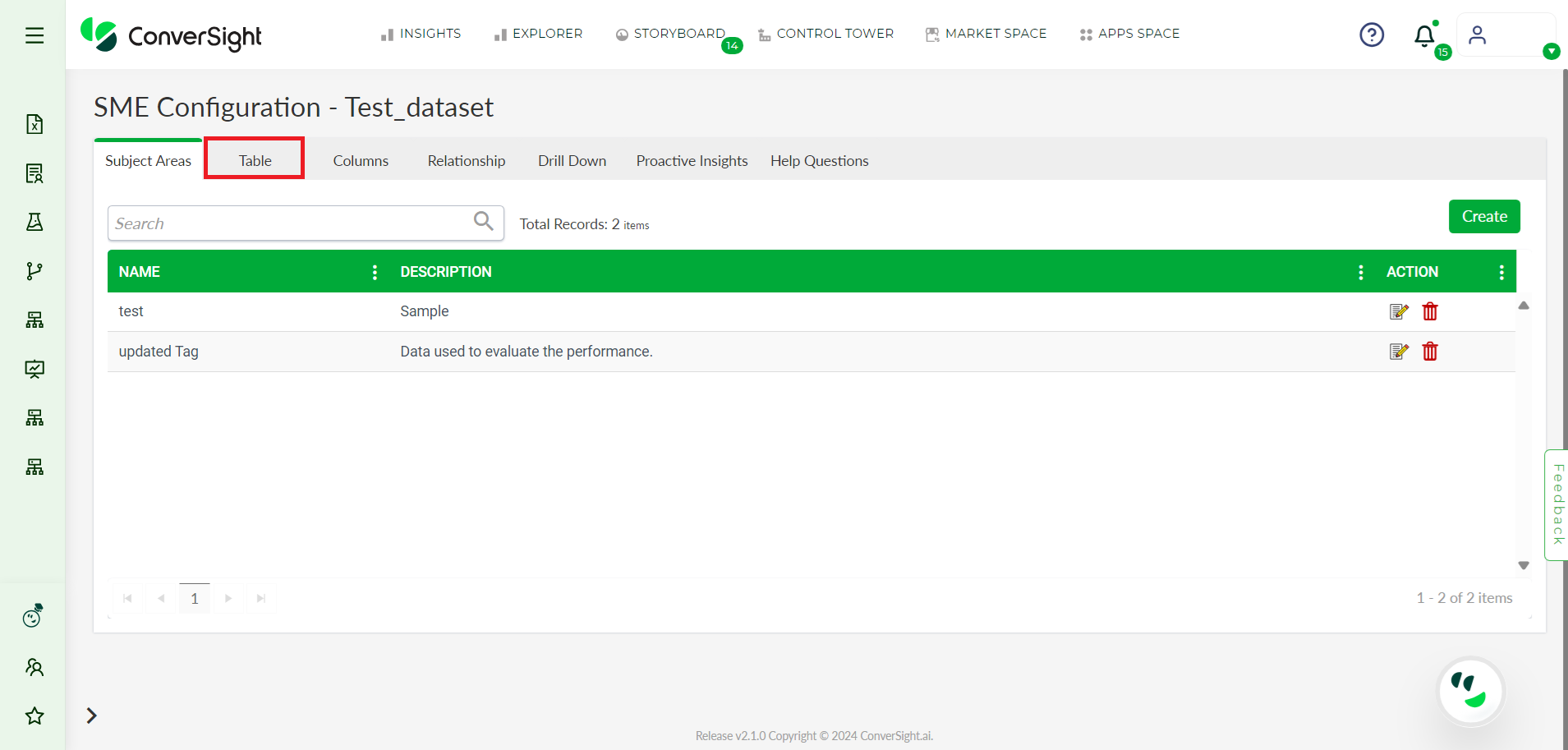
Table Tab#
Step 4: Click on the Calculated Fields button.
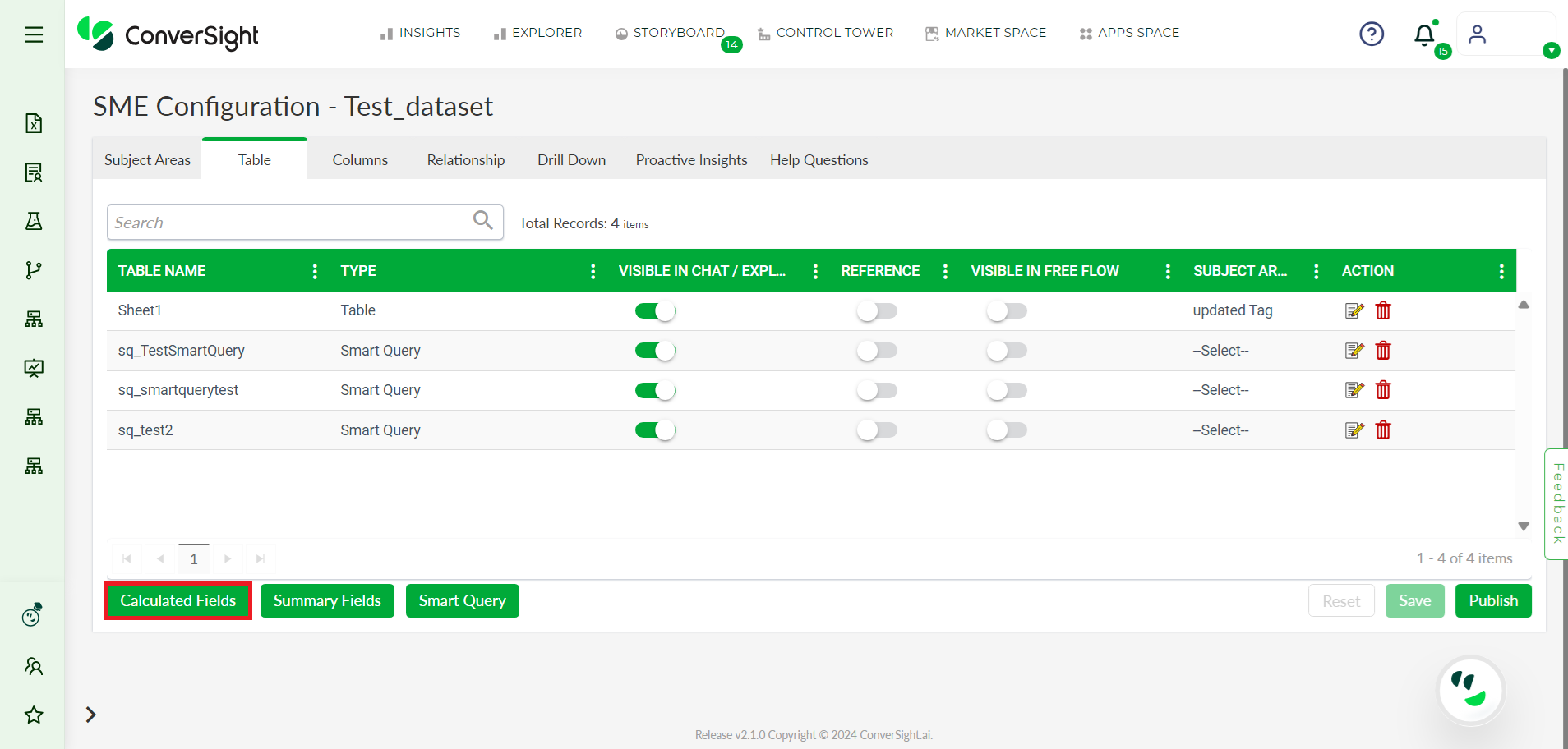
Calculated Fields#
Step 5: In the Calculated Fields tab, Provide a name for your Calculated Fields, then select the category from Category drop-down.
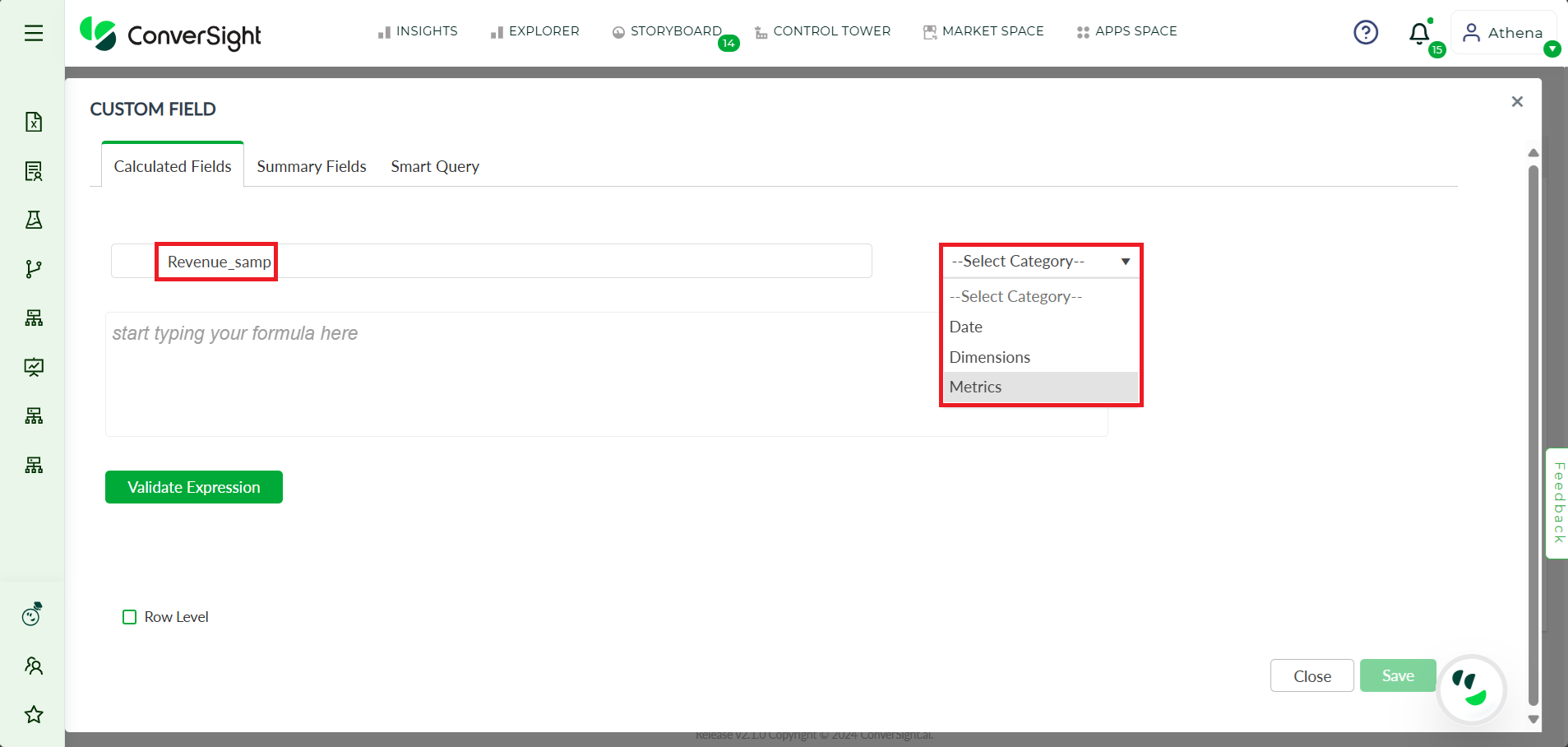
Create Custom Field#
Step 6: Once you’ve named and categorized your Calculated Fields, you can enter your operations in the text box provided.
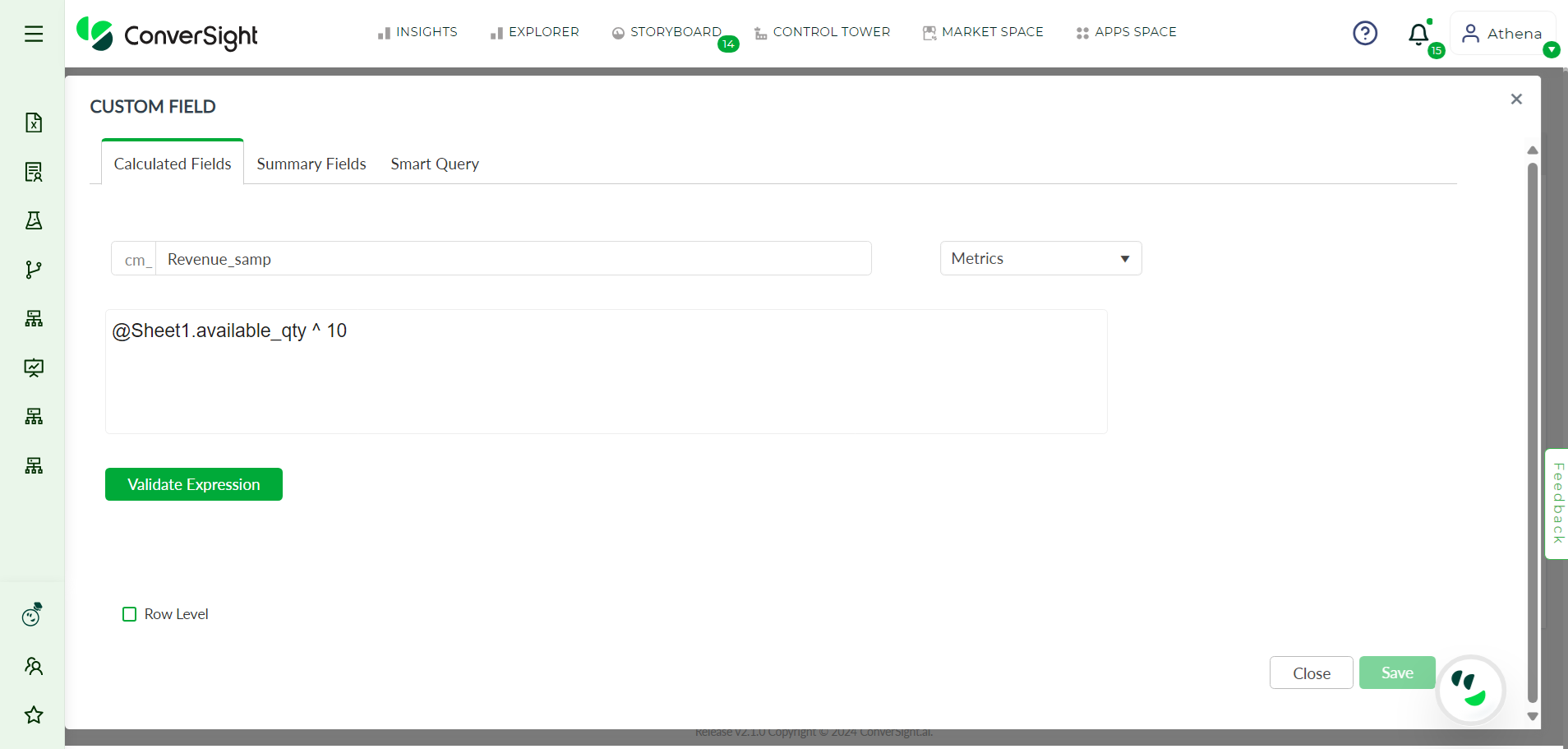
Calculated Field#
The category dropdown presents users with several options for categorizing their columns to refine their search. These options include Metrics, Dimensions and Date.
The Metrics option allows users to perform arithmetic operations on their queries. This option is particularly useful when dealing with numerical data and provides a way to calculate aggregates such as sum, average and maximum.
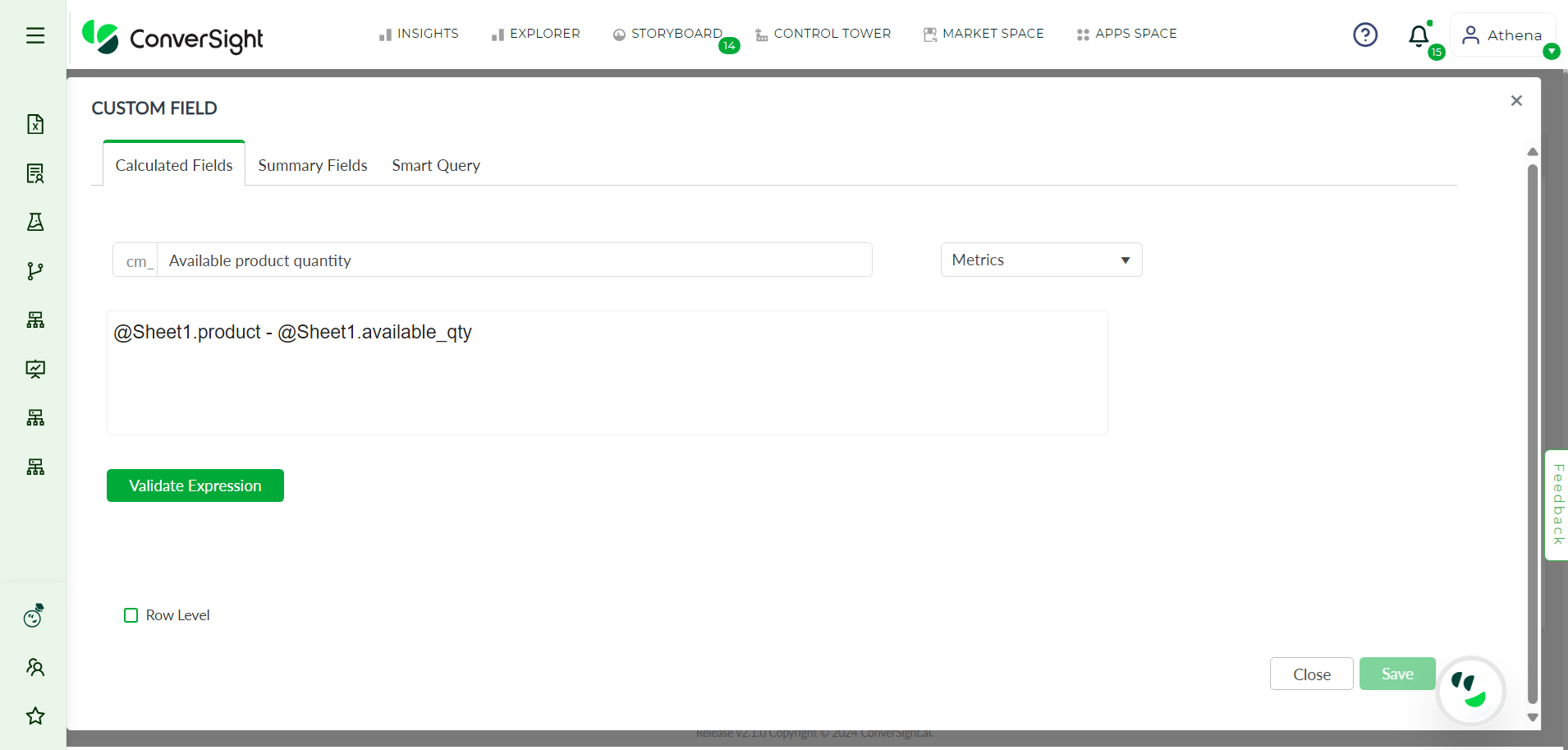
Example for Metrics#
The Dimensions option, on the other hand, enables conditional operations on columns. This option is useful for slicing and dicing data to examine trends and patterns. For example, users can use the Dimension option to group data by specific categories such as region, product or customer.
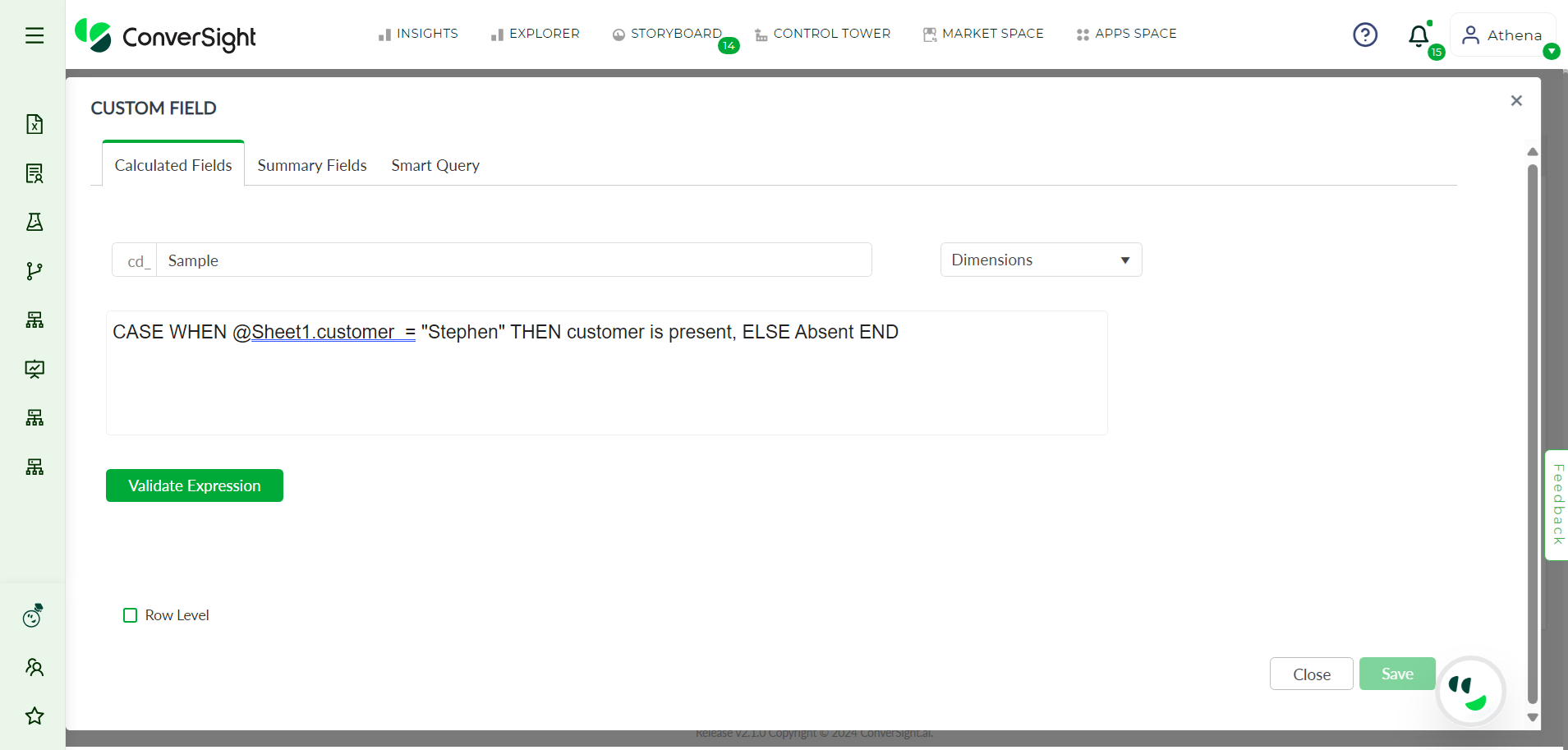
Example for Dimensions#
Finally, the Date option enables users to perform date-related operations on their queries. This option is particularly useful when working with time-series data and provides a way to calculate metrics such as year-over-year growth or month-to-date sales.
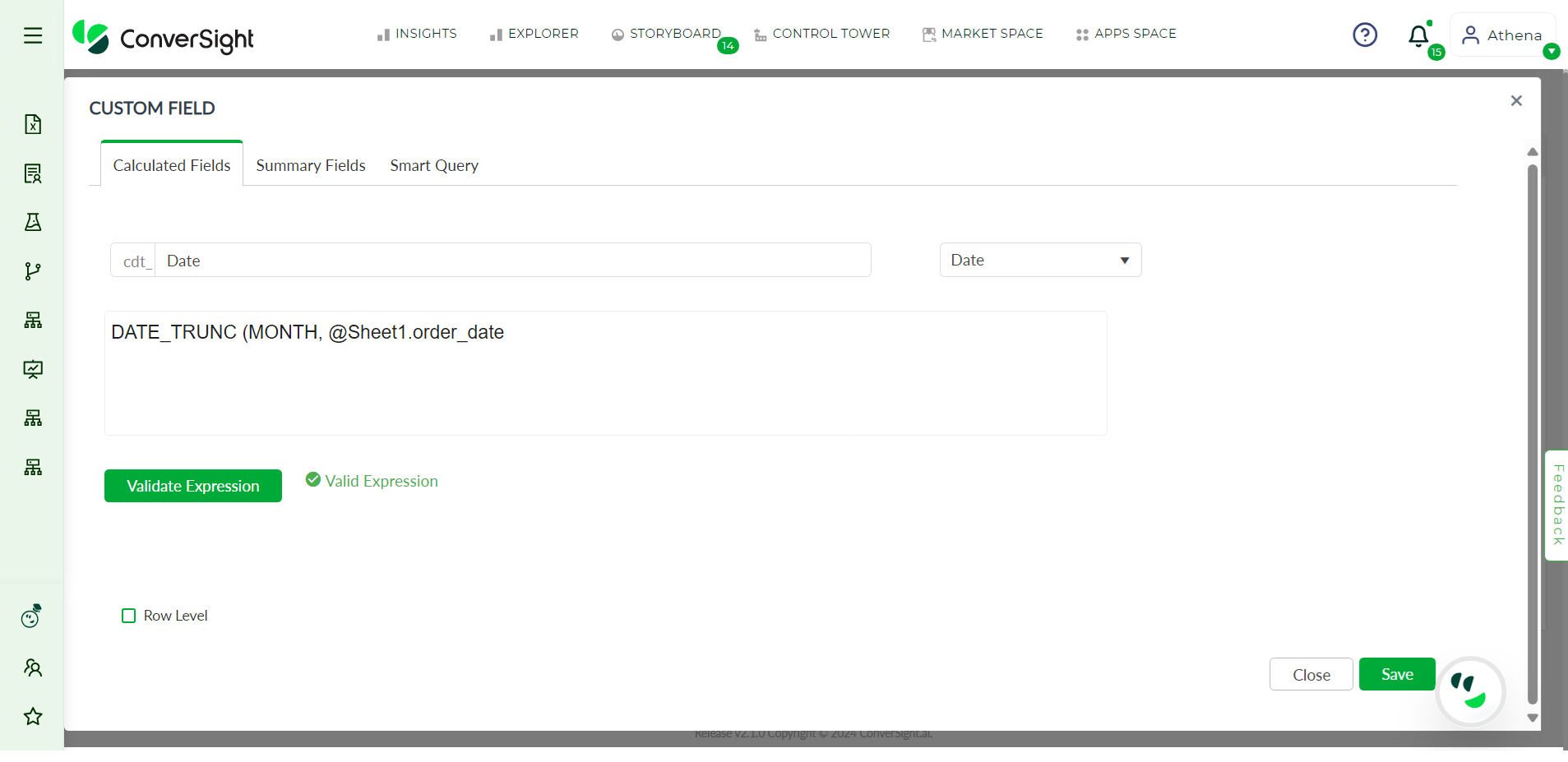
Example for Date#
You can choose to perform operations at the row level by selecting the Row Level checkbox, which will apply the operations to each row before aggregating them at the column level.
NOTE: Row level can be applied only for Metrics Column.
In case the Row Level checkbox is not selected, the operation will be carried out by first aggregating the values by column and then performing the operation.
Step 7: You can validate your expression by clicking on the Validate Expression button.
Step 8: After validating your expression, you can save your Calculated Fields by clicking on the Save button.
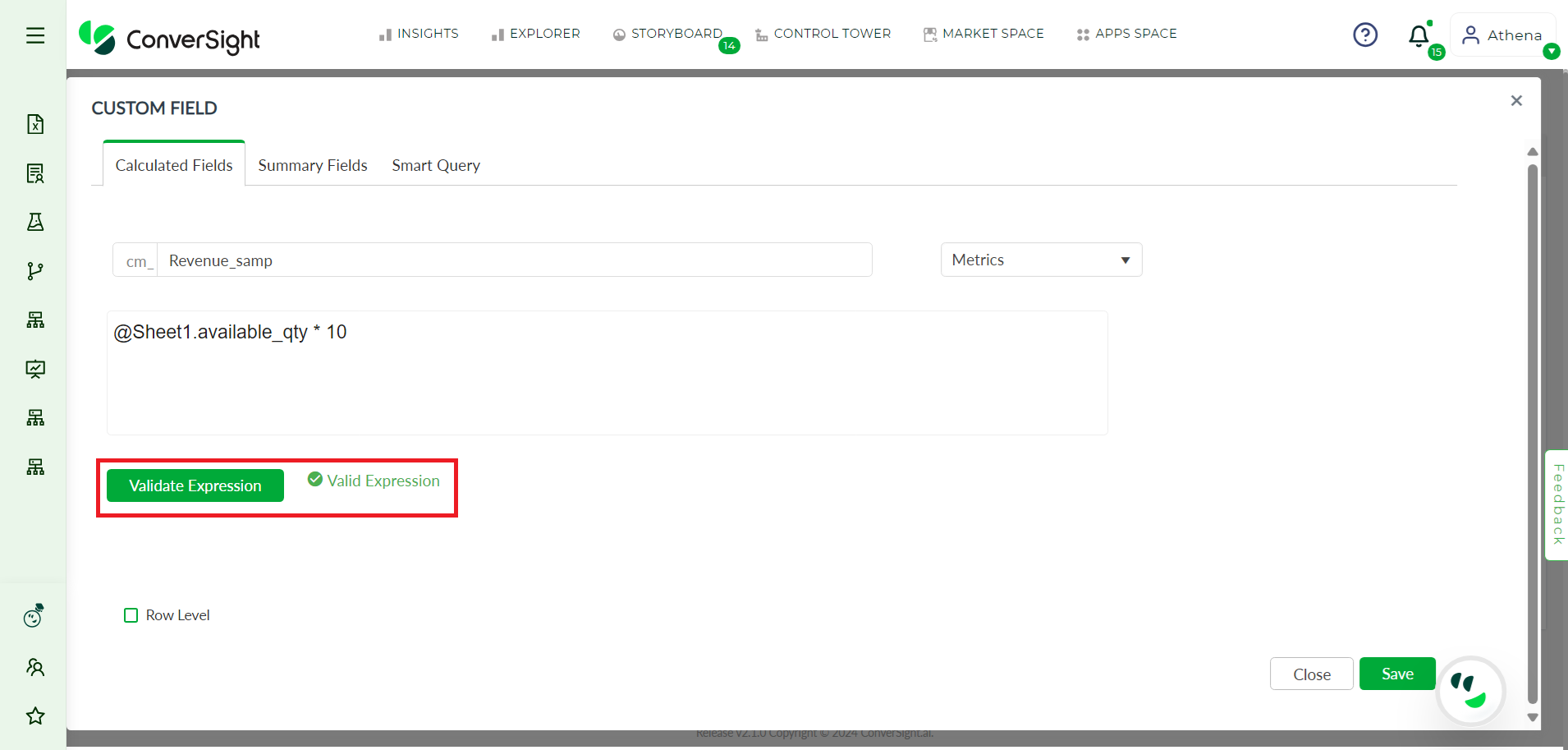
Save Changes#
Step 9: The page will then redirect to the SME coaching page, where you need to publish your Calculated Fields by clicking the Publish button.
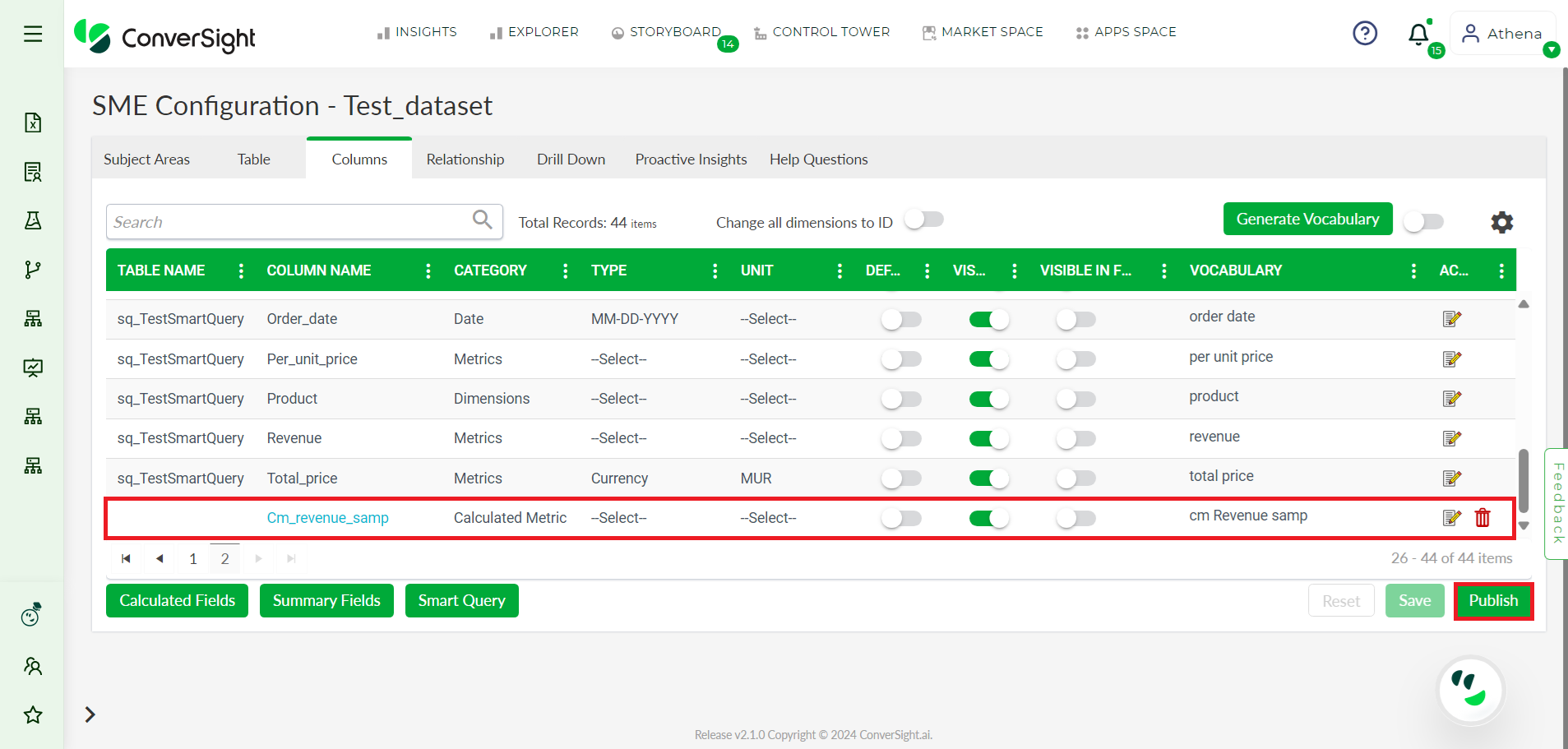
Publish#
Step 10: After publishing your Calculated Fields, you can access it in the data table. You will be able to perform analyzes and gain insights based on the Calculated Fields you have created.
By following these simple steps, you can easily work with Calculated Fields in your business and perform complex analyzes on your data table. This can help you make informed decisions and gain a competitive advantage in your industry.
Guidelines for Formulating Calculated Fields#
Custom Fields are created by applying conditions and executing operations on pre-existing data fields. The general syntax for creating Calculated Fields is
CASE
WHEN condition1 THEN result1
WHEN condition2 THEN result2
WHEN condition N THEN result N
WHEN result
END
NOTE: Calculated Fields do not permit the use of expressions that yield negative values.
Arithmetic Operators#
Arithmetic operators perform mathematical calculations. You have the flexibility to employ all arithmetic operations like addition,subtraction, multiplication and division when creating Calculated Fields.
Operator |
Description |
|---|---|
ColumnName1 + ColumnName2 |
Sum of ColumnName1 and ColumnName2. |
ColumnName1 - ColumnName2 |
Difference of ColumnName1 and ColumnName2. |
ColumnName1 * ColumnName2 |
Multiplication of ColumnName1 and ColumnName2. |
ColumnName1 / ColumnName2 |
Quotient (ColumnName1 divided by ColumnName2). |
ColumnName1 % ColumnName2 |
Remainder (ColumnName1 divided by ColumnName2) |
The syntax for utilizing arithmetic operators in order to construct Calculated Fields is as follows.
@TableName.ColumnName1 Arithmetic operator @TableName.ColumnName2
@TableName.ColumnName Arithmetic operator Desired value
Comparison Operators#
Comparison operators are used to compare two columns or a column with a value. The result of a comparison operation is typically a boolean value.
Operator |
Description |
|---|---|
= |
Equal to: Assesses equivalence of values in a specified column. |
<> or != |
Not equal to: Assesses non-equivalence of values in a specified column. |
> |
Greater than: Evaluates if the value on the left is greater than the right. |
>= |
Greater than or equal to: Determines if the value on the left is equal to or greater than the right. |
< |
Less than: Ascertain if the value on the left is smaller than the right. |
<= |
Less than or equal to: Assess whether the value on the left is less than or equal to the right. |
Is null |
Checks if a value in the specified column has no value or is missing. |
Is not null |
Verifies whether a value in the specified column is not null, indicating it has a value and is not missing. |
between |
Determines if a value falls within a specified range, inclusive of both lower and upper bounds in the specified column. |
not between |
Evaluates if a value does not fall within a specified range, excluding both lower and upper bounds in the specified column. |
The syntax for using these operators are as follows :
When the comparison operator returns true, it shows result 1 and when it’s false, it shows result 2.
CASE
WHEN @TableName.ColumnName1 Comparison Operator @TableName.ColumnName2 THEN result1
ELSE result2
END
CASE
WHEN @TableName.ColumnName Operator Desired VALUE THEN result1
ELSE result2
END
Date/Time Functions#
Date and Time functions simplify the management of date and time data by enabling actions like extracting components, computing durations and adjusting timestamps, streamlining tasks related to temporal data.
Function |
Description |
|---|---|
CURRENT_DATE or CURRENT_DATE() |
Returns the current date in the GMT time zone. |
CURRENT_TIMEor CURRENT_TIME() |
Returns the current time of day in the GMT time zone. |
CURRENT_TIMESTAMP or CURRENT_TIMESTAMP() |
Returns the current timestamp in the GMT time zone. |
DATEADD(‘date_part’, interval, date | timestamp) |
Returns a date after a specified time/date interval has been added. |
DATEDIFF(‘date_part’, date, date) |
Returns the difference between two dates, calculated to the lowest level of the date_part you specify. For example, if you set the date_part as MONTH, only the year and month are used to calculate the result. Other fields, such as day, hour and minute are ignored. |
DATEPART(‘date_part’, date) |
Datepart function is used to extract a specific part or component from a date or timestamp. |
DATE_TRUNC(date_part, timestamp) |
Rounds down a date or time to a specific part like month, day or hour. |
INTERVAL ‘count’ date_part |
Adds or Subtracts count date_part units from a timestamp. Note that ‘count’ is enclosed in single quotes and it can be either Timestamp or date column. |
NOW() |
Return the current timestamp in the GMT time zone. Same as CURRENT_TIMESTAMP(). |
TIMESTAMPADD(date_part, count, timestamp | date) |
Adds a specific date_part count to a timestamp or date. |
TIMESTAMPDIFF(date_part, timestamp1, timestamp2) |
It is used to calculate the difference between two timestamps based on a specified date part. |
EXTRACT(date_part FROM timestamp) |
Extracts specific parts (e.g., year, month, day) from a full date or timestamp. |
Supported date part types:#
DATEDIFF [year, quarter, month, day, hour, minute, second, millisecond, microsecond, nanosecond, week]
DATE_TRUNC [year, quarter, month, day, hour, minute, second, millisecond, microsecond, nanosecond, millennium, century, decade, week,quarterday]
EXTRACT [year, quarter, month, day, hour, minute, second, millisecond, microsecond, nanosecond, dow, isodow, doy, epoch, quarterday, week, week_sunday, dateepoch]
Supported interval types:#
DATEADD [decade, year, quarter, month, week, weekday, day, hour, minute, second, millisecond, microsecond, nanosecond]
DATEPART [year, quarter, month, dayofyear, quarterday, weekday, day, hour, minute, second, millisecond, microsecond, nanosecond]
TIMESTAMPDIFF [year, quarter, month, weekday, day, hour, minute, second, millisecond, microsecond, nanosecond]
Accepted Date, Time and Timestamp Formats:
Data Types |
Format |
Example |
|---|---|---|
Date |
MM:DD:YYYY |
03:28:2023 |
Date |
DD:MM:YYYY |
30:03:2023 |
Date |
YYYY:MM:DD |
2023:31:10 |
Date |
YYYY:DD:MM |
2023:31:03 |
Time |
HH:MM:SS |
12:32:24 |
Time Stamp |
Date Time |
20-OCT-23 16:58:32 |
String Functions#
String functions enable efficient manipulation of text data, including tasks like concatenation, searching and formatting.
Function |
Description |
|---|---|
BASE64_ENCODE(str) |
Encodes a string to a BASE64-encoded string. |
BASE64_DECODE(str) |
Decodes a BASE64-encoded string. |
CHAR_LENGTH(str) |
Char_length function returns the number of characters in a string. |
str1||str2 |
Returns the string obtained by concatenating the specified strings. It’s important to note that numeric, date, timestamp and time types will be automatically converted to strings as needed. Therefore, explicit casting of non-string types to string types is unnecessary when using the concatenation operator with these inputs. |
INITCAP(str) |
Produces a string in which the first letter, as well as any subsequent letters following defined delimiter characters, are in uppercase, while the remaining characters are in lowercase. Accepted delimiter characters include !, ?, @, “, ^, #, $, &, ~, _, ,, ., :, ;, +, -, *, %, /, |, , [, ], (, ), {, }, <, >. |
KEY_FOR_STRING(str) |
Key_for_string function returns the dictionary key of a dictionary-encoded string column. |
LCASE(str) |
Returns the string in lowercase, with current support limited to the ASCII character set. Equivalent to the LOWER function. |
LENGTH (str) |
Length function returns the length of a string in bytes. |
LOWER(str) |
Returns the string in lowercase, with current support limited to the ASCII character set. Equivalent to the LCASE function. |
LEFT(str, num) |
Provides the leftmost specified number (num) of characters from the string (str). |
LPAD(str, len, lpad_str ) |
Left-pads the string (str) with the specified padding string (lpad_str) to achieve a total length of len. If lpad_str is not provided, the space character is used for padding. If the length of str exceeds len, characters from the end of str are truncated to match the length of len. The padding process involves adding characters from lpad_str sequentially until the desired length len is reached. If the concatenation of lpad_str and str is insufficient to meet the target len, lpad_str is repeated, potentially in partial segments, until the desired length is achieved. |
LTRIM(str, chars) |
Removes leading characters defined in chars from the string. Functions identically to the TRIM operation. |
OVERLAY(str PLACING replacement_str FROM start FOR len) |
In the given string (str), this operation substitutes a specified number of characters (len) starting from the specified position (start) with the characters defined in replacement_str. The replacement involves removing len characters from str and inserting the replacement_str, unless the combined length of start and replacement_str exceeds the length of str. In such cases, all characters from the start position to the end of str are replaced. If the start value is negative, it indicates the number of characters counted from the end of str. |
POSITION( search_str IN str FROM start_position) |
Provides the position of the initial character in the search_str within the str, with the option to commence the search from start_position. Returns 0 if search_str is not located. Returns null if either search_str or str is null. |
REPEAT(str, num) |
Duplicates the string based on the specified repetition count(num). |
REPLACE(str, existing_substr, new_str) |
Updates the string by replacing every instance of the substring from_str with the new substring new_str. |
REVERSE(str) |
Reverses the given string. |
RIGHT(str, num) |
Provides the rightmost specified number (num) of characters from the string (str). |
RPAD(str, len, rpad_str) |
Pads the string on the right with the specified string (rpad_str) to achieve a total length of len. If rpad_str is not provided, space characters are used for padding. If the length of str exceeds len, characters from the start of str are truncated to match the length of len. The padding involves adding characters from rpad_str sequentially until the desired length len is reached. If the concatenation of rpad_str and str is insufficient to meet the target len, rpad_str is repeated, potentially in partial segments, until the desired length is achieved. |
RTRIM(str) |
Removes any trailing spaces from the string. |
SPLIT_PART(str, ‘delim’, field_num) |
Divide the string using a specified delimiter (delim) and retrieve the field identified by the field number (field_num). Fields are numbered sequentially from left to right. |
STRTOK_TO_ARRAY(str, ‘delim’ ) |
Splits the string, str, into tokens using optional delimiter(s), delim and provides an array of these tokens. If no tokens are generated during the process, an empty array is returned. If either parameter is NULL, the result is also NULL. |
SUBSTR(str, start, len) or SUBSTRING(str FROM start FOR len) |
Returns a substring of the string (str) starting at the index specified by start and extending for len characters. The indexing is 1-based, meaning the first character of str is at index 1 (not 0). However, start 0 is equivalent to start 1. If start is negative, it denotes start characters from the end of the string. If len is not provided, the substring from start to the end of str is returned. If start + len exceeds the length of str, the characters in str from start to the end are returned. |
TRIM( BOTH | LEADING | TRAILING trim_str FROM str) |
Removes characters defined in trim_str from the beginning, end or both of str. If trim_str is not specified, the space character is the default. If the trim location is not specified, defined characters are trimmed from both the beginning and end of str. |
TRY_CAST( str AS type) |
The TRY_CAST function tries to change a string into a numeric, timestamp, date or time format. If it succeeds, you get the converted value; if it fails (for example, if the string isn’t in a valid format for the chosen type), you get null. Just remember, TRY_CAST only works for converting strings. |
UCASE(str) |
Provides the string in uppercase format, with current support limited to the ASCII character set. Equivalent to the UPPER function. |
UPPER(str) |
Returns the string in uppercase, with current support limited to the ASCII character set. Equivalent to the UCASE function. |
Pattern Matching Functions#
Pattern matching functions are functions in SQL that allow you to search for specific patterns or substrings within text or character data. These functions are commonly used to query, filter or manipulate data based on matching patterns in strings.
Function |
Description |
Syntax |
|---|---|---|
like |
Returns true if the string matches the pattern. |
Case when @TableName.ColumnName like ‘%Pattern%’ then result1 else result2 end |
not like |
Returns true if the string does not match the pattern. |
Case when @TableName.ColumnName not like ‘%Pattern%’ then result1 else result2 end |
ilike |
Used for case-insensitive pattern matching, ignoring letter case. |
Case when @TableName.ColumnName ilike ‘%Pattern%’ then result1 else result2 end |
regexp |
Used for complex text pattern matching with POSIX regular expressions. |
Case when @TableName.ColumnName regexp ‘posix_pattern’ then result1 else result2 end |
regexp_like |
Checks if a string matches a specified POSIX regular expression pattern. |
Case when regexp_like(@TableName.ColumnName, ‘Posix_pattern’) then result1 else result2 end |